Look Who’s Talking: AI in Video Conferencing

Artificial intelligence (AI) is not only revolutionizing how we design technology, but how we use it. For example, AI is being integrated in everyday solutions like video conferencing systems.
These systems use facial recognition to track those who are speaking and adjust camera angles to capture them entirely within the frame. They automatically display speaker names, titles, and other biographical information. Some even determine participant engagement through human pose analysis and gesture recognition.
Collaboration systems that integrate natural language processing can transcribe calls or translate speech into other languages in real time. And “virtual assistants” take notes, pull up relevant files, and schedule conference calls.
Designing these capabilities into commonplace devices like video conferencing systems can add real value. But it also can present significant engineering challenges, especially where latency is concerned.
The Latency Issue
Anyone who has used Siri or Alexa will admit the noticeable delay between asking a question and receiving a response from the system. That’s because most of the natural language processing in those systems is handled in the cloud.
Collaboration systems need voice, video, and any AI functions delivered in real time. Otherwise quality will suffer almost immediately. To avoid the added latency, AI must be supported locally on an on-premises video conferencing system.
Running AI locally is easier said than done, particularly in cost- and power-sensitive video conferencing systems. In part this is because image and speech recognition are typically based on multilayered neural network algorithms. And to compute each layer, a processor has to access memory frequently to retrieve data from input devices like cameras or microphones (Figure 1).
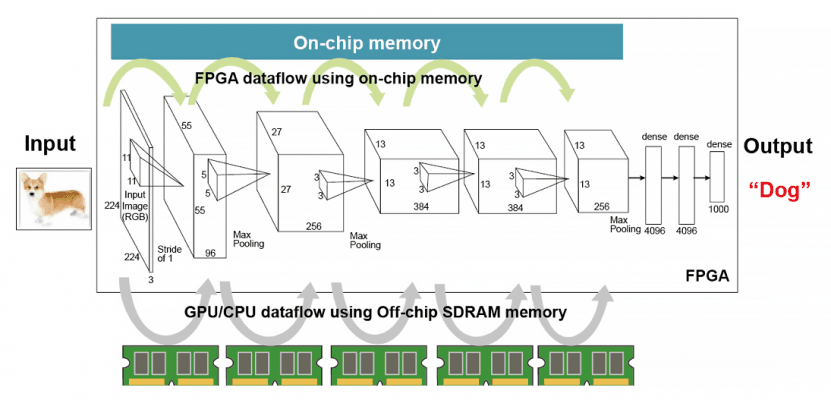
This is the first of many design decisions. Selecting an AI processor like a GPU will also require discrete DRAM, which adds latency, power consumption, and heat generation because of the frequent memory accesses. It also contributes to the overall bill of materials.
Another option is to choose a compute device with integrated memory, such as an FPGA or dedicated workload accelerator. These can offset the cost of a processor-plus-memory architecture and reduce power and latency, but are often difficult to program.
And on the software side, image and speech recognition algorithms must be optimized for size, speed, and accuracy. This helps meet video conferencing system requirements and maximizes the underlying hardware.
Design Services Bring It Together
Integrating all of this with the core functionality of a video conferencing system can overwhelm the time-to-market requirements of enterprise OEMs. But partnering with an experienced product engineering firm can add product value while still keeping pace with market expectations.
One manufacturer looking to add image and speech recognition functionality to its video conferencing offerings chose this path by teaming with VVDN Technologies.
VVDN Technologies is an engineering design services and manufacturing company that specializes in image signal processing (ISP), video analytics, video stitching, and multi-sensor integration. For the video conferencing market, the company has also developed a range of real-time edge AI capabilities.
Working with the enterprise video conferencing supplier, VVDN helped develop a 180º field of view (FOV) fanless camera system that integrates advanced convolutional neural network (CNN) algorithms. These AI algorithms also support image and speech recognition applications such as voice capture, human pose analysis, gesture recognition, and more.
VVDN used two Intel® Movidius™ Myriad X Vision Processing Units (Intel® VPUs) as the main compute elements of the camera (Figure 2). The Myriad X processors integrate a suite of dedicated hardware accelerators and an on-chip intelligent memory fabric to minimize latency, power consumption, and cost.

The AI processing pipeline on Myriad X VPUs begins with 16 MIPI lanes that support up to eight HD resolution cameras. Once image or video data is acquired over these interfaces, it is passed to integrated hardware encoders that support 4K resolutions at 30 Hz and 60 Hz frame rates.
Data can then pass into high-throughput imaging and vision hardware accelerators, an array of 16 programmable vector processors, a dedicated AI workload processor called the Neural Compute Engine, or any combination of the three.
What ties all of these processing components together is a shared on-chip intelligent memory fabric. This means that data can traverse the ISP pipeline without computational elements having to repeatedly access additional memory blocks. Direct memory access (DMA) also allows more than one compute element to access the shared memory simultaneously, enabling parallel processing on one or more video streams.
As a result, Myriad X processors help minimize the power consumption, heat generation, and cost associated with other architectures. In fact, the devices consume just 2.5 W of power, and are significantly less expensive than many discrete GPU and FPGA offerings.
AI Integration at Work
In the VVDN AI video conferencing system design, the Myriad X VPUs capture HD video from two inputs at 30 frames per second (fps). MobileNet facial detection, gesture recognition, and human pose analysis CNN algorithms are then executed on one of the VPU’s Neural Compute Engines, which performs inferencing at up to 4 fps. From there, the analyzed video is streamed over the device’s USB 3.1 interface.
The second Myriad X processor handles voice processing, integrating a wake-word engine tuned to the OEM’s specific AI voice service. This enables accurate, ultra-low-latency automatic speech recognition (ASR) on the video conferencing device, even in noisy real-world environments.
The dual VPUs also stitch together two 4K video streams to enable a number of advanced video capabilities, including auto-framing, participant zoom, and picture-in-picture (PiP).
Thanks to software optimizations performed by VVDN, all of this was achieved using just 12 MB of system memory.
Bringing AI to Devices Near You
The co-designed video conferencing system demonstrates both the challenges and possibilities of integrating advanced AI capabilities into the next generation of everyday electronic devices.
From a consumer perspective, these systems must add significant value to existing solutions without sacrificing performance or user experience. From a vendor perspective, advanced AI capabilities cannot impact the bottom line. For design engineers, this means developing architectures that keep latency, power consumption, heat, and cost to a minimum.
Through strategic partnerships and AI-optimized technology solutions like Myriad X VPUs, everyone can benefit from smarter devices.