Fill form to unlock content
Error - something went wrong!
Get the latest on IoT and network edge for smart cities.
You are following this topic.
Using a Hyperscaler in an Edge AI Project? Read This First

So you want to build an AI system. Where do you start?
Take multimodal sentiment analysis, for example, which relies on multiple natural language processing and/or computer vision models that are refined through rigorous data labeling and training. Implementing it in, say, a retail customer service kiosk requires infrastructure like databases and visualization tools, web app development environments, deployment and delivery services, and, of course, an AI model training framework or two.
If this is your first foray into AI-enabled system creation, your organization probably doesn’t have all these tools configured in a way that’s conducive to fast AI system prototyping—if it has all the necessary components at all. In these instances, AI engineering hopefuls often turn to hyperscaler cloud platforms like Microsoft Azure, AWS, and Google Cloud. In addition to essentially infinite data capacity and infrastructure services, many of these hyperscalers support end-to-end AI development out of the box or offer API-based integration for specific third-party tools in a few clicks.
And best of all, you can get started for relatively cheap and add capabilities later as-a-service. So why assemble an ecosystem of technology partners when you can get started so quickly and easily on your own?
Hidden Cost of Hyperscalers for Edge AI Engineers
In early-stage proof of concepts (PoCs), hyperscaler cloud platforms are great for fleshing out ideas. But as you move into prototyping that more closely resembles the end product, their limitations are quickly exposed.
“What is difficult with hyperscalers is a real bespoke PoC because hyperscalers are based on standards. You use those standards, or you don’t use the hyperscaler,” says Glenn Fitzgerald, Chief Data Officer in the Product Business at Fujitsu Limited, a global information and communication technology company. “That applies both to the infrastructure and the application stacks that they use.”
“There’s also the issue of data sovereignty and residency, which isn’t so relevant in PoCs but certainly is if you get to prototyping,” Fitzgerald continues. “The hyperscalers don’t like you taking data out of their clouds and structure to avoid it. Legal and regulatory issues can significantly complicate data-driven projects, those that use AI in a hyperscaler environment.”
#AI #technology depends on increasing amounts of data being funneled into training models to improve the accuracy and performance of neural networks, making #edge-core-comms and #data management critical factors. @Fujitsu_Global via @insightdottech
The data is the key. AI technology depends on increasing amounts of data being funneled into training models to improve the accuracy and performance of neural networks, making edge-core-comms and data management critical factors. Data storage is a key revenue generator for hyperscalers.
It’s not hard to imagine starting an AI PoC in a hyperscaler environment with a few images, only to have it balloon into multiple databases with hundreds of thousands of images as prototypes evolve. And since extracting data from a hyperscaler cloud can be difficult, what began as innocuous platform selection can quickly become a costly platform trap.
An AI Identity Crisis
At this point you should also be asking whether you need to develop AI at all. For example, most companies don’t sell sentiment classification. Instead, they use it as an enabler of solutions like retail kiosks or market research software. That’s because, out of the box, AI isn’t a solution but rather a new capability that can solve existing problems.
“AI is not a solution to anything,” Fitzgerald explains. “If you think of AI in its traditional meanings of machine learning or natural language processing or neural networks, 99% of the time it’s a component in a solution, not a solution in and of itself.
“Where companies should start is, ‘This is my business issue.’ Far too many of them start with, ‘I need to be doing AI.’” says Fitzgerald. “But if you start with, ‘We need to do AI,’ you’ll end up doing nothing.”
In many cases, a better strategy is to leverage technology ecosystems that offload the overhead of AI model creation while keeping costs low. Done right, this approach allows OEMs and system integrators to capitalize on AI’s advantages while concentrating on the end application.
Accelerate AI Inference with a Partner Ecosystem
Fujitsu, in collaboration with Intel and British consultancy Brainpool.AI, has established a partnership to provide an onramp for AI prototypers. Called “co-creation workshops,” companies can access Brainpool.AI’s collection of more than 600 leading AI academics who advise on infrastructure components required to achieve the desired outcome. Fujitsu operates as an integrator, orchestrating additional partners and establishing the necessary infrastructure to scale AI from PoC through prototyping.
To facilitate this process, Fujitsu created AI Test Drive, a purpose-built AI infrastructure based on web app components, data services, monitoring tools, and AI suites from SUSE Linux, NetApp, and Juniper Networks. This software is packaged in a demo cluster that runs on Intel® processor-based servers and lets users stress-test AI designs while retaining 100% control of their data for curation, ingestion, and cleaning.
Free trials of AI Test Drive can be accessed through a portal. To deliver best-in-class model accuracy, latency, and performance across the gamut of AI use cases, it makes use of the Intel® OpenVINO™ Toolkit. The toolkit is an AI model optimization suite that compresses and accelerates different neural network software generated in different environments for use on different hardware. It’s compatible with the Open Model Zoo so that pre-trained models can be imported easily into prototyping pipelines.
As shown in Figure 1, OpenVINO accelerated an FP32 BERT sentiment classification model by 2.68x compared to the same unoptimized PyTorch FP32 model.
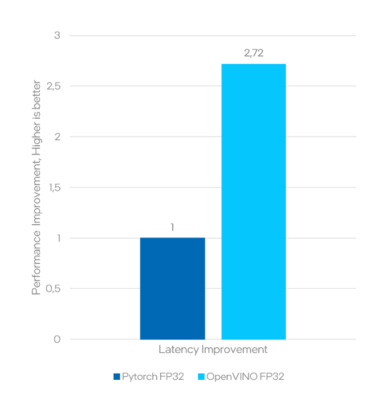
“You have to build an ecosystem that’s appropriate to the problem you’re trying to solve,” Fitzgerald says. “An organization like Fujitsu, which can bring other organizations into it and cover all those bases, is how you get the optimum team to solve a problem,” says Fitzgerald.
Start with the Business Problem
Today there’s an industry-wide fear of missing out on edge AI, visual AI, and machine learning. But before getting carried into the frenzy, understand how to avoid chasing red herrings into competencies that aren’t your own.
“Start with the business problem,” Fitzgerald advises. “If you understand the business problem, then you can work with your stakeholders, your trusted partners, and third parties to solve that problem.”
Edited by Georganne Benesch, Associate Editorial Director for insight.tech.