IoT Data Analytics: The Layer Cake

Many sensing devices on the edge (where the internet meets the real world) can generate humongous quantities of raw data. The trick is to convert this raw data into actionable information.
Raw IoT data comes from many sources and arrives in many forms. Some data may be sequential, captured in real time, and delivered using a wide variety of communication mechanisms and protocols. In other cases, batch data may originate in databases or content management systems, or arrive in the form of comma separated value (CSV) files.
IoT applications are predicated on making this data usable and actionable. But capturing data of so many different shapes and sizes can be challenging, especially for systems based on centralized relational databases like SQL that work best with highly structured data.
Many IoT solutions today rely on the cloud for data storage and analysis, but the cloud is not a panacea for every problem:
- Bandwidth isn’t free. It costs money to send every single sample of data to the cloud.
- Latency is a concern. Some systems require real-time monitoring and control.
- Connectivity isn’t always available. For some applications, being able to operate independently of cloud connectivity is a must.
In the same way that sources of incoming data may be diverse and highly distributed, so must be the database and analytics solutions that process this data.
In a distributed processing model some processing is performed at the edge, some is performed in the fog (a small, local cloud), and some is performed in the cloud itself (Figure 1). This means that if a sensor is cut off from its host for any reason, it can continue to gather data while waiting for its connection to be restored. Similarly, if a facility loses its connection to the cloud, it can continue to operate locally in the fog, re-synchronizing with the cloud when its connection to the outside world is restored.
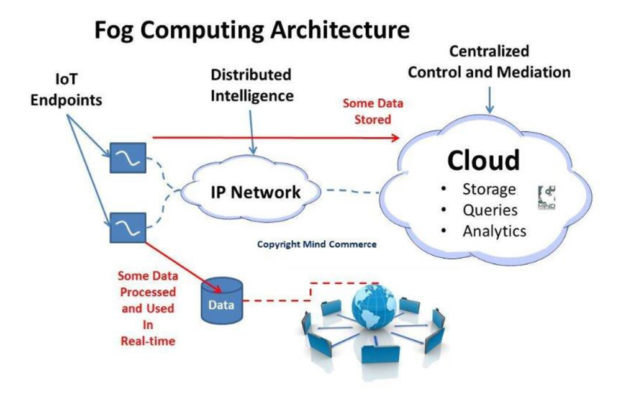
Figure 1. Distributed IoT data processing helps reduce costs and improve reliability. (Source: Universitat Oberta de Catalunya)
A distributed processing reduces risk to keeps things moving, so do distributed analytics solutions that can perform magic at the edge, in the fog, and in the cloud. @SkyFoundry
Analytics Everywhere
Just as distributed processing reduces risk and keeps things moving, so does a distributed analytics solution that can perform its magic at the edge, in the fog, and in the cloud.
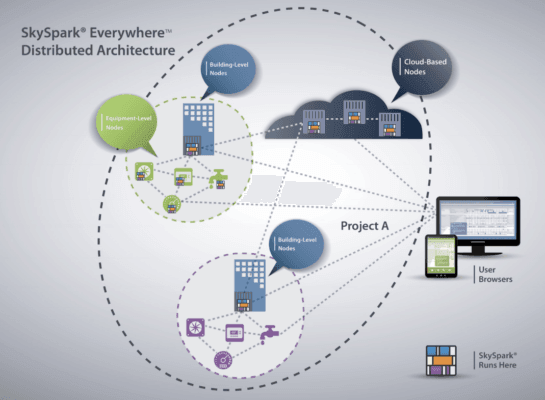
Consider the SkySpark from SkyFoundry. This open, distributed data analytics solution can collect, store, analyze, and present data from IoT endpoints across the edge-to-cloud continuum (Figure 2).
When it comes to ingesting data of all types, the SkySpark platform supports a wide range of industry protocols, including Modbus TCP, BACnet IP, MQTT, Obix, and OPC UA. These packets are encapsulated in a websocket-based peer-to-peer communications protocol called Arcbeam that enables communications between distributed nodes and databases like SQL and CSV/Excel.
SkySpark also features a Folio Time Series Database, sometimes called a process historian. This database is designed to accept large volumes of high-speed sensor data in the form of analog or digital samples, setpoints, and commands. Compared to off-the-shelf relational databases like MySQL and MS-SQL, the Folio Time Series Database is architected to provide optimal processing of timestamped sensor data without any tradeoffs.
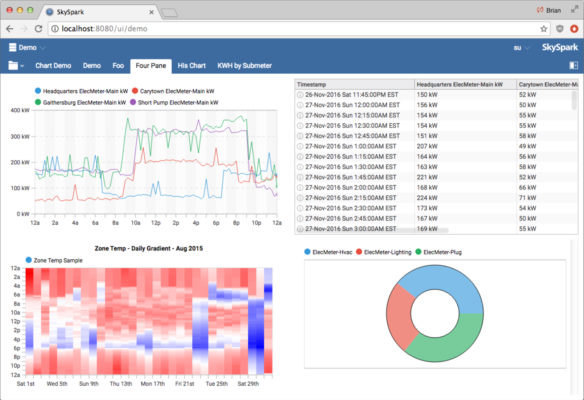
Data extracted from the Folio Time Series Database can then be extracted and displayed in user-configurable SkySpark visualization dashboards (Figure 3).
On the back end, the SkySpark informatics platform provides a library of more than 500 stock analytics functions that can be applied to data captured on distributed nodes. It also integrates an analytics engine called Axon that allows domain experts to implement rules and algorithms that best fit the needs of their unique applications, systems, and devices.
These analytics algorithms can help engineers identify patterns, deviations, faults, and opportunities for operational improvement in nodes all the way from the edge to the fog to the cloud.
Even with all its capabilities and power, SkySpark requires a minimum of just 512 MB of system RAM and a 1 GHz clock speed — in other words, a device capable of supporting a Java virtual machine (VM). This makes the technology ideally suited for the scalable computing requirements of end-to-end IoT deployments that rely on Intel Atom® processors at the edge, Intel® Celeron® or Intel® Core™ processors in the fog, or Intel® Xeon® processors in the cloud.
Multilayered Intelligence for Advanced Insight
Real IoT value is generated by comparing data from multiple locations (buildings, factories, farms, etc.) that are in the same business, use similar machines, and/or employ comparable practices. For example, when it is determined that an anomalous temperature profile coupled with an unusual vibration pattern resulted in a certain fault on a particular type of machine in one location, then observing similar activity on the same type of machine in a completely different location may trigger pre-emptive maintenance. This minimizes downtime and reduces costs.
Even more value can be obtained by gathering, analyzing, and correlating data over time. And this does not simply mean “starting now.” In many cases, it’s possible to access historical data going back years or even decades. Such historical data can be mined by sophisticated analytics algorithms to uncover “hidden gems” and provide a wealth of insights.
Distributed, multilayered data analytics that work from the edge to the cloud can identify complex relationships among seemingly unrelated inputs, detecting trends that are indicative of future problems, offering predictions, and providing solutions.