Double AI Performance in Surveillance Servers
AI and machine learning can add tremendous value to large-scale surveillance systems—such as those deployed in smart cities. Machine intelligence can help ease traffic congestion, monitor sensitive locations, and perform a host of other duties.
For example, one emerging field of AI-based video surveillance is behavioral analytics, whereby surveillance systems “learn” the typical behavior of a monitored environment (such as a sidewalk) and report anomalous events (such as a car parked on the curb). Taking this a step further is event-driven surveillance, in which a series of actions (such as a person entering a restricted area outside of a designated time) triggers a response (such as an audible announcement warning intruders that they are trespassing).
Such capabilities require considerable computational performance, which has traditionally been available only in large data center environments. The challenge this poses for system operators is that streaming video consumes a significant amount of network bandwidth, resulting in high transmission costs. Certain applications may also suffer from the additional latency associated with piping video to a third-party data center.
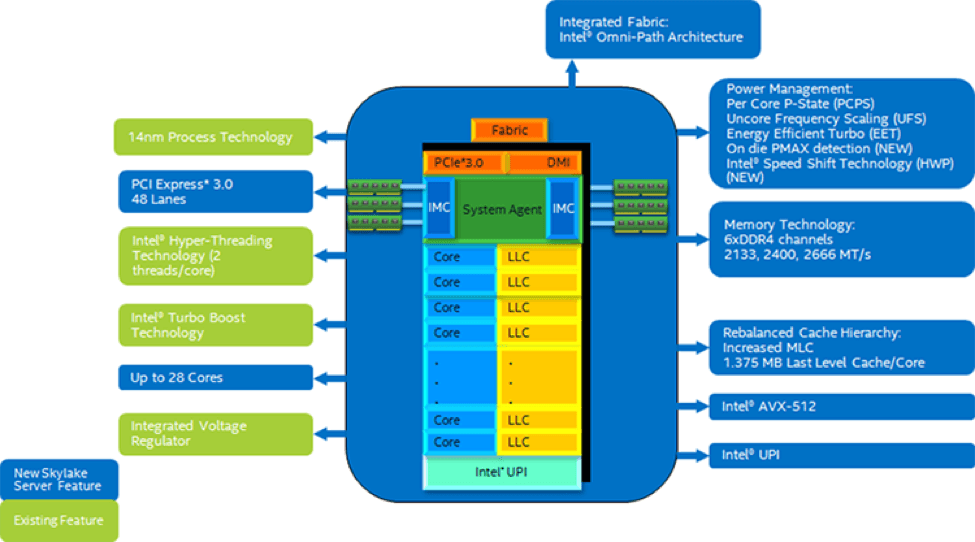
One solution for operators looking to deploy artificially intelligent surveillance systems is the new Intel® Xeon® Scalable family line (formerly codenamed “Purley”), which more than doubles AI workload performance. As illustrated in Figure 1, key features of the platform include:
- Up to 28 cores per socket, up from a maximum of 24 cores in the previous generation
- Intel® Advanced Vector Extensions 512 (Intel® AVX-512), which doubles matrix math throughput
- A new mesh interconnect architecture that reduces latency and improves memory bandwidth
- The next-generation Intel® Omni-Path Architecture (Intel® OPA) switching fabric technology to scale to tens of thousands of nodes
In short, Xeon® Scalable Processors enable creation of advanced edge servers that meet evolving smart city requirements.
Twice the Compute Throughput for AI Closer to the Edge
The performance upgrades start with up to 28 cores per socket for as many as 224 cores in an eight-socket system, with clock speeds ranging from 1.9 GHz to 3.6 GHz per core. In addition, each core supports Intel® AVX-512 SIMD instructions.
While Intel® AVX-512 instructions are not a first for Intel® processors (originally introduced in the Intel® Xeon Phi™ product line), they offer twice the compute throughput of Intel® AVX/AVX2 thanks to several new 512-bit instructions that target high-performance computing (HPC) workloads. For surveillance in particular, AVX512DQ instructions enhance integer and floating-point operations in ray tracing, double-precision matrix multiplication, fast Fourier transform (FFT), and convolutional workloads indicative of video analytics and AI applications.
To support these more sophisticated instructions, two fused multiply-add (FMA) units have been upgraded from 256 bits to 512 bits. The FMA units improve precision in complex floating-point operations by computing entire expressions as a + b * c and then rounding down to the nearest significant bit. This provides higher-resolution outcomes in signal processing applications such as video analytics, as well as other programs that involve the accumulation of multiple inputs like convolutional and deep neural networks (CNNs and DNNs).
Together, the performance increases in new Intel® Xeon® Scalable Processors represent at 2.2x improvement in deep learning training and inferencing over the previous generation, critical for AI-based video analytics.
Mesh Interconnect Reduces Latency to Maximize DSS Performance
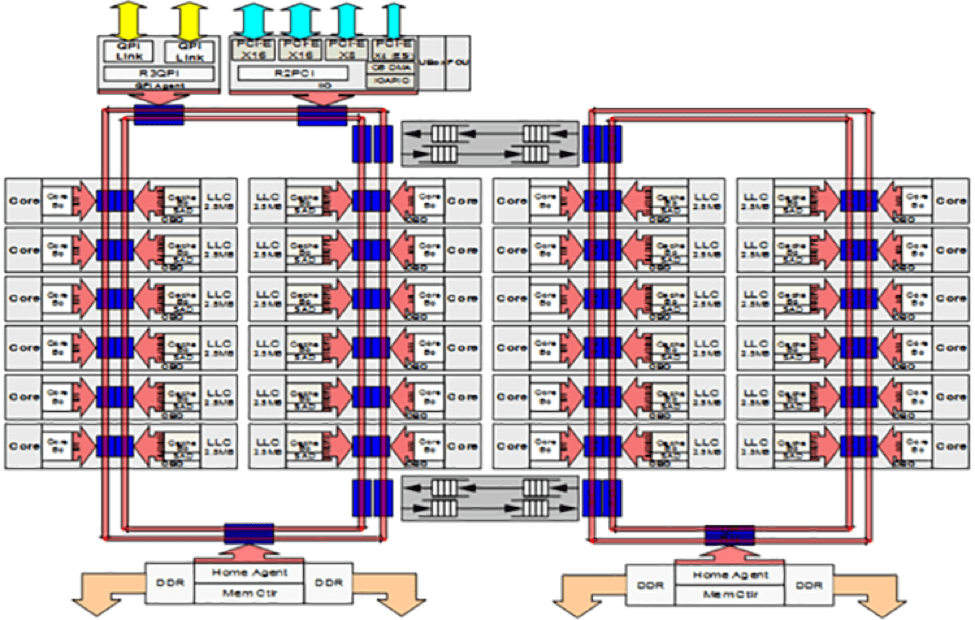
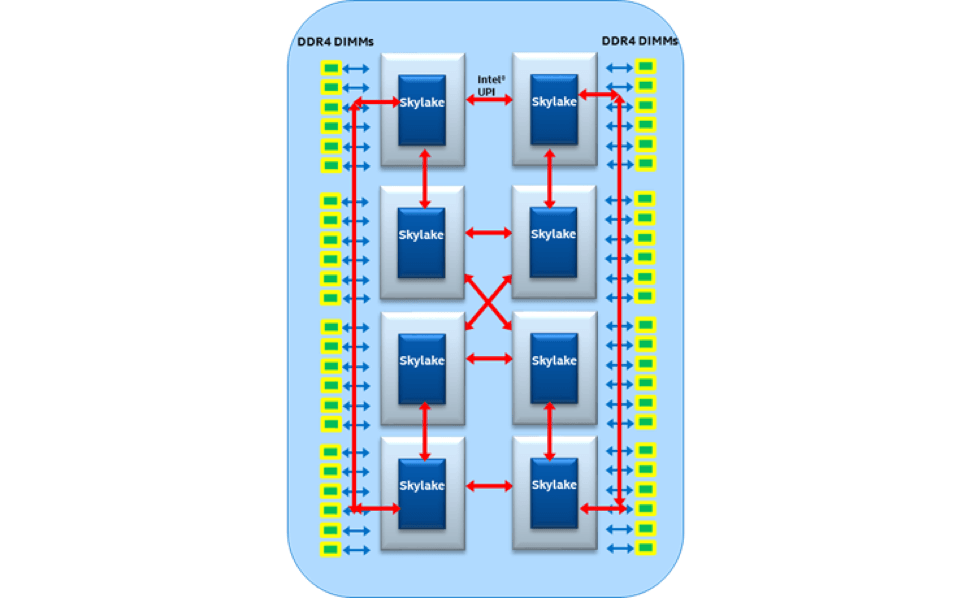
To maximize the performance provided by the increased number of cores and integrated acceleration functions of Intel® Xeon Scalable Processors, the 14 nm Skylake-SP microarchitecture features a new on-chip mesh interconnect topology that reduces the latency of core-to-core communications.
As shown in Figures 2A and 2B, the mesh interconnect replaces the ring topology of previous-generation microarchitectures so that communications can occur over the shortest possible vertical/horizontal path. A caching agent, home agent, and I/O subsystem are also integrated into the mesh so that cores can benefit from reduced latencies when accessing these functions as well.
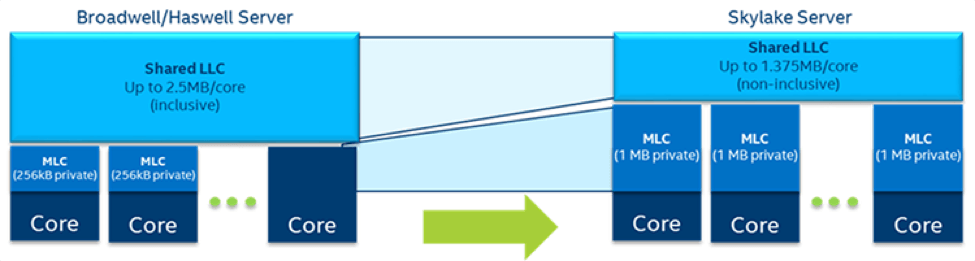
A redesigned cache hierarchy also doubles the amount of L1 cache, increases the L2 cache to 1 MB, and reduces the last level cache (LLC) to a non-inclusive 1.375 MB per core (Figure 3). Reallocating more cache closer to the core shrinks the memory access latency of Xeon® Scalable Processors, while the transition to a non-inclusive LLC results in better overall memory utilization.
For surveillance applications with high cache hits, these features result in a 1.5x memory bandwidth improvement. Memory performance is further supported by six channels of 2133 to 2666 MHz DDR4 SDRAM and up to 1.5 TB of memory capacity per CPU.
Scaling to Exascale
Surveillance servers are typically multi-chip, multi-socket systems, and therefore require high-speed, low-latency communications between sockets and server racks, as well as between cores.
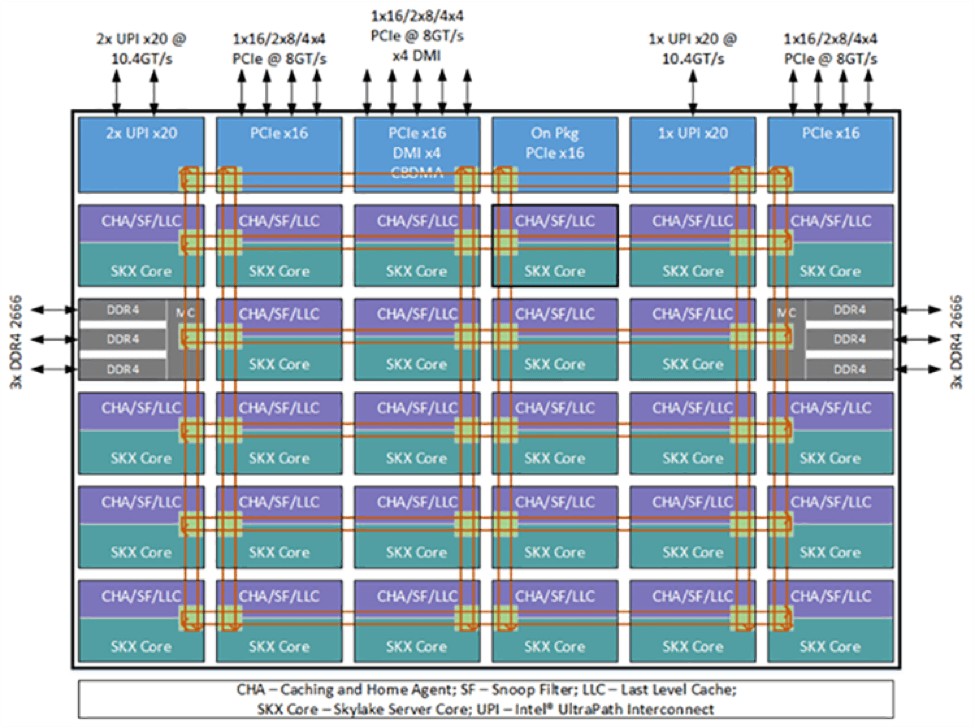
For chip-to-chip communications, Intel® Xeon® Scalable Processors deliver considerable high-speed I/O enhancements, including 48x PCIe 3.0 lanes per CPU, up to 14 SATA3 ports, 10 USB 3.0 ports, and an integrated Intel® Ethernet Connection X722.
But to keep multi-socket communications on par with the performance enhancements of Intel® Xeon® Scalable Processors, the Intel® Quick Path Interconnect (Intel® QPI) has been replaced by two or three Intel® Ultra-Path Interconnect (Intel® UPI) per processor. Intel® UPI is a coherent interconnect technology that provides 10.4 GTps socket-to-socket data transfer speeds, and integrates a combined caching and home agent (CHA) distributed in each core and LLC bank to ease scalability (Figure 4).
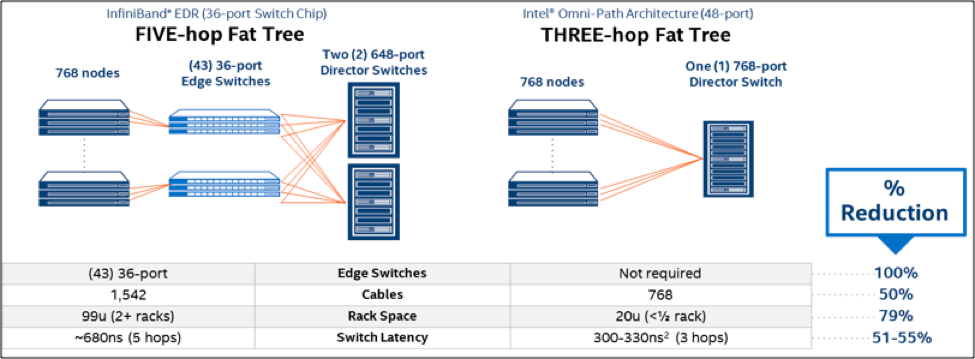
Beyond single systems, Intel® Xeon® Scalable Processors support the Intel® Omni-Path Architecture (Intel® OPA), a price-competitive successor to Intel® True Scale Fabric and InfiniBand that provides 100 Gbps line rates and can scale to support 10,000-plus nodes.
Intel® OPA is significant in that it reduces the hardware required to support exascale computing while maintaining software compatibility with legacy switching technologies. The integration of features such as adaptive/dispersive routing, traffic flow optimization, dynamic lane scaling, and packet integrity protection in a single technology precludes the need for edge switches, minimizes rack space, and cuts cabling in half, which results in significant cost savings and maintenance reductions (Figure 5).
Intel® OPA technology is available as an integrated feature of certain Intel® Xeon Scalable Processor SKUs, or is accessible through add-in cards that can be dropped into surveillance server designs.
Surveillance Server Building Blocks
DSS server solutions based on Intel® Xeon® Scalable Processors are already available from original equipment manufacturers (OEMs) serving the embedded and networking markets.
One example is the Ennoconn NSB-1021, an integrated network motherboard that supports up to two 24-core Intel® Xeon® Scalable Processors, two Intel® C620 series companion chipsets, up to 48 PCI Express 3.0 lanes per CPU, and six channels of high-speed DDR4 SDRAM in a thermal design power (TDP) envelope as low as 70 W (Figure 6).

Thanks to the versatility of the new Intel® Xeon® Scalable Processors and features such as Intel® UPI and Intel® OPA, surveillance system developers can start with versions of the NSB-1021 that target price and performance per watt, then scale up to banks of localized server arrays as demand increases.
Smarter Surveillance with Intel® Xeon® Scalable Processors
As surveillance systems integrate advanced technologies such as AI to meet the needs of smart cities, reducing network transmission costs and achieving lower latency are two areas that must be addressed. One way to accomplish both is through surveillance servers capable of executing video analytics that can be placed closer to the video source.
While the ability to execute advanced video analytics and AI workloads hasn't been available beyond the data center, new Intel® Xeon® Scalable Processors provide surveillance and smart city operators an alternative that puts intelligence closer to the edge. Surveillance just got smarter.