Machine Learning Gets a 2.2x Performance Boost
Machine learning is revolutionizing industrial automation: Collaborative robots (cobots) learn manufacturing processes from human workers and then perform them more efficiently. AI-equipped machines self-diagnose imminent component failures and request maintenance. And this is only the beginning.
Of course, applications like these require enormous compute power. That makes the arrival of Intel® Xeon® Scalable Processors (formerly codenamed “Purley”) a major milestone for AI. With up to 28 cores per socket and new Intel® Advanced Vector Extensions 512 (Intel® AVX-512) instructions, these chips provide a 2.2x improvement in deep learning training and inferencing over previous-generation processors.
For industrial servers, this next generation of performance is supported by a new mesh interconnect architecture, cache memory design, software tools, and off-the-shelf board solutions that can expedite creation of AI-based applications.
AVX-512: The AI Workhorse
From an AI perspective, the most significant new feature of Intel® Xeon® Scalable Processors is support for Intel® AVX-512 instructions, which doubles the floating-point operations per cycle over previous processors. In particular, new additions to the SIMD instruction set are tailored to accelerate compute-intensive workloads generated by AI and machine learning applications.
Notably, this boost in throughput comes without a power penalty. As illustrated in Figure 1, Intel AVX-512 offers considerably higher performance per watt than previous SIMD extensions, allowing significantly greater performance at the same power level and lower clock speeds.
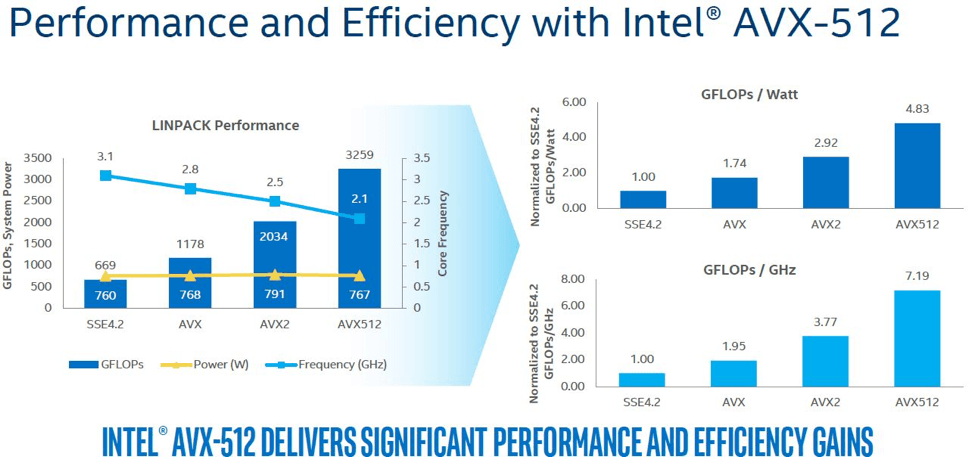
Also notable are two 512-bit fused multiply-add (FMA) units per processor core, which accelerate one of the most common operations in machine learning and AI algorithms.
Of course, higher core counts help. The new chips boast up to 28 cores per socket, compared to a max of 24 cores on the previous generation.
Inteconnect and Memory Leaps Forward
To support the horsepower present in the Intel® Xeon® Scalable Processors, L2 cache has been quadrupled from 256 KB in the previous processors to 1 MB in Purley. Adding more cache memory closer to the core results in considerably reduced memory access latencies, which in turn leads to significantly faster application response time in demanding computational tasks like machine learning, data compression, and motion tracking.
Intel also opted for a range of updated core architectural enhancements in the new Skylake-SP microarchitecture of the new Intel® Xeon® Scalable Processors. These include a new on-chip mesh interconnect architecture, an upgraded socket-to-socket interconnect technology, and expansive I/O.
In terms of on-chip connectivity between cores, a new cache-coherent mesh interconnect architecture replaces the ring topology of earlier Intel® Xeon® processors to reduce communications latency in industrial servers. Rather than passing core-to-core communications along a dedicated communications path around the chip, the mesh architecture enables data transfer across the shortest possible X/Y axis (Figure 2). This helps maximize the compute performance for intense workloads that need to access data or be executed on multiple cores.
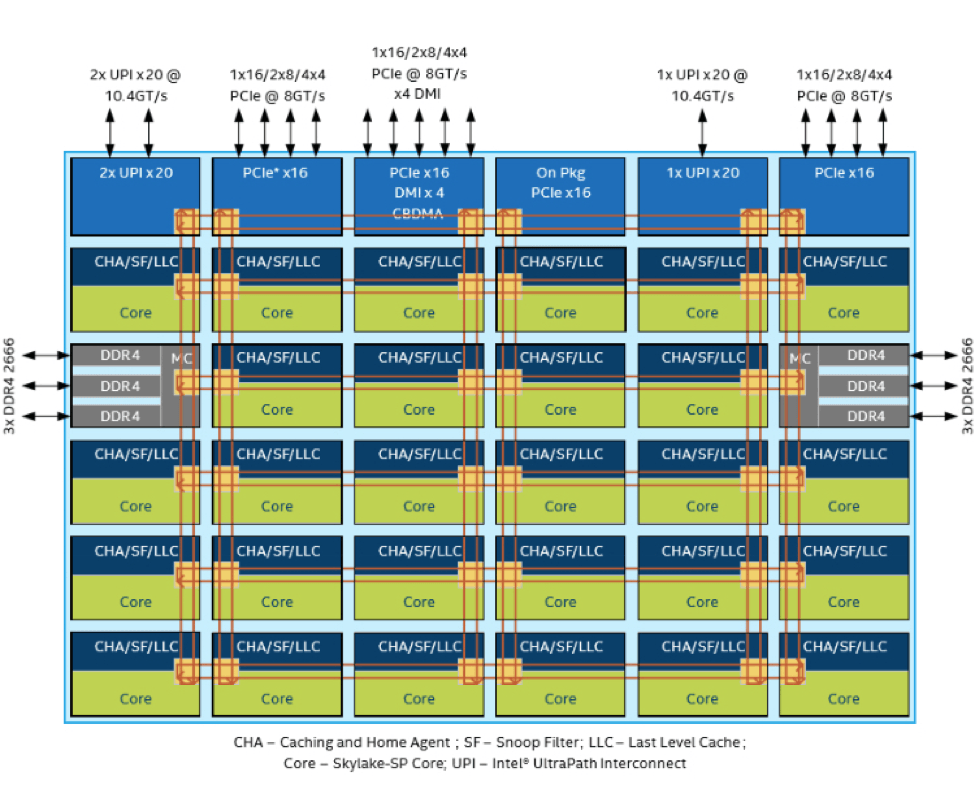
For industrial server designs that demand multi-socket performance, Intel also moved on from its QuickPath Interconnect (QPI). The upgraded Intel® UltraPath Interconnect (Intel® UPI) can deliver socket-to-socket line rates of 10.4 GTps to offer multi-processor scalability for AI training and inferencing. Up to three Intel® UPI ports are available on each Intel® Xeon® Scalable Processor, which facilitate easy scaling of many-core industrial server designs over time.
In addition, the new Intel® Xeon® processors support 48 PCIe 3.0 channels, integrated 4x 10 Gigabit Ethernet (GbE), and numerous other high-speed I/Os.
Integrating Advanced Capabilities in Existing Industrial Servers
One example of the performance and flexibility that the next-generation Intel® Xeon® processors provide industrial servers running machine learning workloads is Trenton System‘s SEP8253 HDEC host board. The SEP8253 HDEC host board features two Intel® Xeon® Gold 6100 Series processors that are part of the Intel® Xeon® Scalable Processor portfolio.
The SEP8253 board is a plugin networking card that brings out all of the compute and throughput capabilities of Intel® Xeon® Scalable Processors by routing all 88 PCIe links from the board's two processors down to double-density PCIe card edge fingers. The PCIe design allows easy integration of the SEP8253 with a wide variety of backplanes and system platforms, including 2U, 4U, and 5U 19 rackmount industrial servers (Figure 3).

The Software Boost
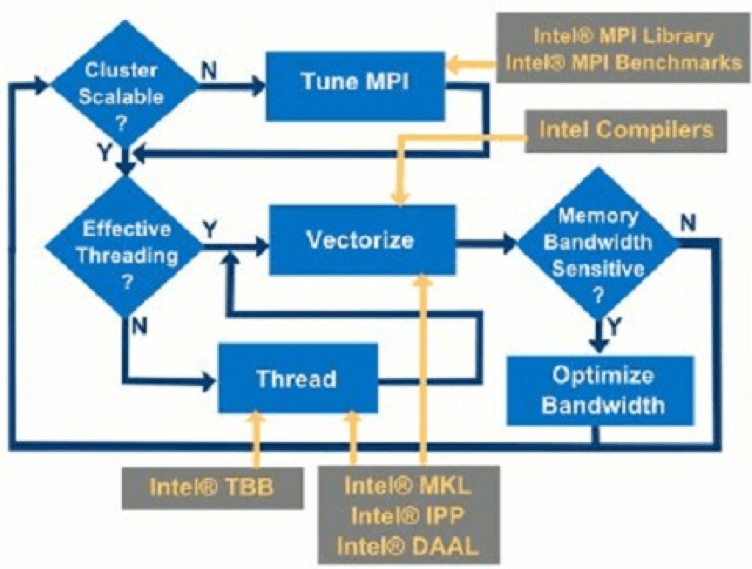
A range of software tools, optimized libraries, foundational building blocks, and flexible frameworks are available that simplify workflows and code creation for developers building AI capabilities on top of Intel® Xeon® Scalable Processors.
The Intel® Parallel Studio XE software development suite, for instance, allows developers to modernize existing codebases for machine learning and AI, as well as boost application performance by taking advantage of new features of Intel® Xeon® Scalable Processors. For example, Intel® Parallel Studio XE 2017 also includes performance libraries like the Intel® Math Kernel Library for Deep Neural Networks (Intel® MKL-DNN) to accelerate deep learning frameworks on Intel® Xeon® Scalable processors. The royalty-free Intel® MKL-DNN software accelerates math processing routines to enhance application performance.
Then there is the Intel® Data Analytics Acceleration Library (Intel® DAAL) that speeds up data analytics. It features highly tuned functions for deep learning, classical machine learning, and data analytics performance while optimizing data ingestion and algorithmic computation for the highest possible analytics throughput (Figure 4).
Intel® Xeon® Scalable Processors are also optimized for popular machine learning frameworks such as Neon, Caffe, Theano, Torch, and TensorFlow.
The Power of Scalability
Intel® Xeon® Scalable Processors represent a huge architectural jump in the company's server-class processing portfolio to support a new generation of workload-heavy applications like deep learning in the industrial automation sector. The highly scalable product line includes platforms that range from cost-effective to energy-efficient to high-performance, with many options guaranteed for 15 years.
Automation engineers: An upgrade path to artificially intelligent manufacturing environments has arrived.