Smooth Scaling for AI and CV Across Edge Devices

Editor’s Note: insight.tech stands in support of ending acts of racism, inequity, and social injustice. We do not tolerate our sponsors’ products being used to violate human rights, including but not limited to the abuse of visualization technologies by governments. Products, technologies, and solutions are featured on insight.tech under the presumption of responsible and ethical use of artificial intelligence and computer vision tools, technologies, and methods.
In the 15 years since the company’s multicore pivot, the idea of using more than one Intel® CPU core to increase performance has gone from cutting-edge to common. The emergence of AI has raised some of the same questions that developers dealt with more than a decade ago. But now these questions are in respect to new heterogeneous computing environments that didn’t exist back in 2004.
Unlike a typical CPU, which presents an array of identical cores each suitable for independent execution, the heterogeneous combination of a CPU+GPU, or CPU+FPGA, pairs the compute resources of two or more very different components. While this presents tremendous opportunities for mutually advantageous computing in the right environments, it also raises the difficulty curve for proper deployment.
Toss in the fact that the most useful places to deploy these sorts of rugged IoT solutions are not known to be friendly to the survival of technology more complicated than a fork, and you’ve got a recipe for problems.
(Not a recipe for anything useful, mind you, like a good sourdough. Nope. Just a bunch of problems.)
Properly scaling workloads across multiple solutions requires the know-how to build and deploy the hardware solutions you need and a software environment that allows you develop and test them in the first place. The Intel® OpenVINO™ Toolkit is specifically designed to help companies scale across multiple types of devices as they develop for both homogeneous and heterogeneous compute environments.
The AI and machine learning algorithms baked into OpenVINO receive a lot of attention, but the “V” stands for “Visual,” and many of the toolkit’s capabilities pretrained models relate specifically to computer vision.
Scaling Across Hardware Platforms
OpenVINO is designed to allow workloads to execute across CPUs and attached accelerators, through support for cross-platform APIs like OpenVX and OpenCL (Figure 1).
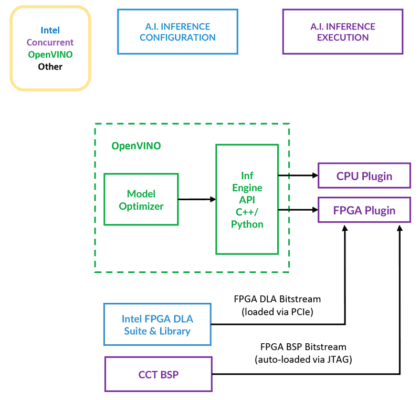
But software without compatible hardware isn’t terribly useful, which is where solutions like the TR H4x/3sd-RCx from Concurrent Technologies come into play. The base system is a 3U VPX system featuring a 12-core/24-thread Intel® Xeon® D-1559 and up to 64GB of RAM.
If these capabilities aren’t sufficient to meet the customer’s needs, there’s an option to attach additional processing resources via PCIe. The TR H4x/3sd-RCx can also be paired with an Intel® Arria® FPGA attached via PCIe for additional processing power.
“The only thing the customer has to know is what neural network model is needed. They select the right DLA bitstream, take their existing model, and run it through OpenVINO.” @ConcurrentPlc
Optimizing Computer Vision Models
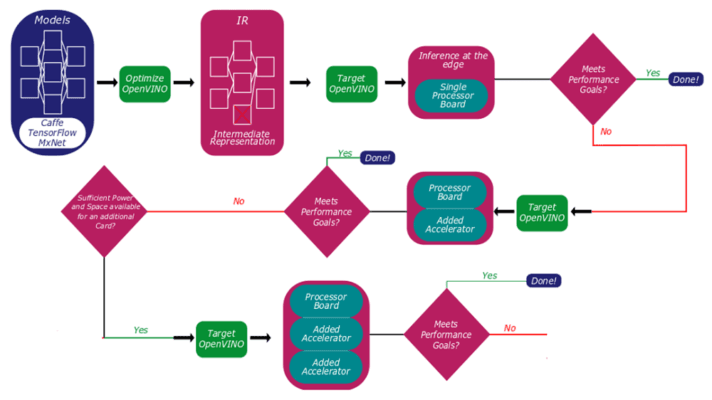
Using OpenVINO, customers can build and optimize a model, and test the performance of their solutions, starting with a single-processor board and expanding as needed to include additional processing resources (Figure 2).
“Moving your model to work on a CPU is easy; we provide a broad Linux support package,” says Nigel Forrester, Director of Business Development at Concurrent Technologies. “Moving your model onto a TR H4x card is a little bit more involved. We provide a board support package pre-loaded on the card, and we also provide the DLAs—the Deep Learning Accelerator bitstreams—that run on the Intel Aria FPGA card.”
“The only thing the customer has to know,” Forrester continues, “is what neural network model is needed. They select the right DLA bitstream, take their existing model, and run it through OpenVINO. This provides an intermediate representation that gets loaded onto the accelerator to make it all work.”
Past that point, OpenVINO handles the project assignments, with CPU-specific code optimized and executed on CPUs, while FPGA code is reserved and run on the Arria hardware.
“We have a developer license for the Intel® Deep Learning Accelerator Suite (Intel® DLA), which we’ve ported to our Trax card,” Forrester tells us. “The customer doesn’t have to do any of that. All they need to know is if their neural network model is in AlexNet, SqueezeNet, GoogleNet, or another, and it’s within a framework such as TensorFlow.”
The graphic above lays out the process of qualifying an OpenVINO model on the Concurrent TR H4x/3sd-RCx hardware. There’s a cycle of optimization, performance testing, and hardware deployment intended to help developers determine what kinds of resources need to be dedicated to which workloads. And OpenVINO will become even more useful over the next few years as new Intel GPUs and inference accelerators come to market, extending the overall flexibility of the software and allowing developers to target a wider variety of use cases and scenarios.