Let the IoT Edge Manage Itself

Today’s IoT customers expect the redundancy, flexibility, and scalability of a centralized cloud architecture at the cost and latency targets of edge computing. If a remote solution requires high levels of reliability, it should have a high-functioning fallback. If an endpoint loses connectivity, it should be able to continue operations until connection is re-established; and a loss of power should not mean a loss of data.
But IoT edge nodes are the definition of a single point of failure, as a loss of connectivity, unstable power supplies, or hardware malfunctions can take an endpoint down at any given time. And unlike cloud data centers, the distributed nature of IoT edge nodes means that IT personnel may not be able to respond for days or weeks if a failure does occur.
As enterprise expectations continue to merge with the realities of the operational edge, IoT system architects are finding a middle ground thanks to hyper-converged infrastructure (HCI).
IoT edge nodes are the definition of a single point of failure. A loss of connectivity, unstable power supplies, or hardware malfunctions could take down an endpoint at any time. @NodeWeaver
@insightdottech
The Best of Cloud and Edge Computing
HCI is an IoT architecture that drives data center-like resources to the edge (Figure 1). By moving data center-like compute, networking, and storage resources closer to edge applications or all the way to the edge itself, HCI can deliver the performance of the cloud in distributed endpoints.
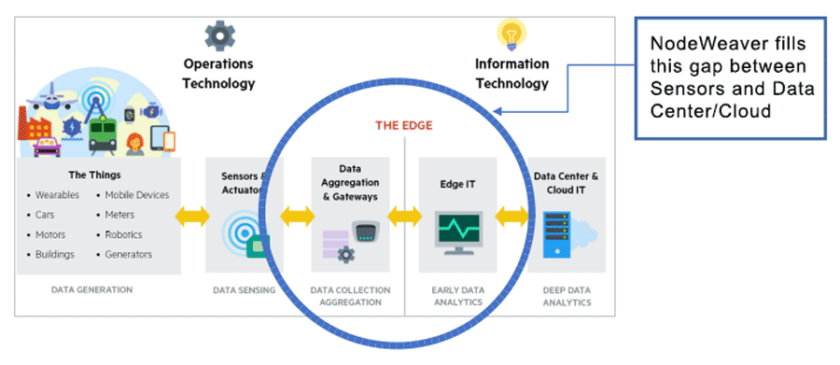
Examples of HCI hardware include high-performance edge gateways based on Intel® Core™ or Intel Atom® processors; mobile edge compute base-stations that will become prominent in 5G networks; and Intel® Xeon®-powered uCPE servers that are already being deployed in on-premises IoT use cases. Read SD-WAN and uCPE: Introduction to learn more.
These platforms are becoming increasingly popular in remote IoT deployments because of their support for multicore processors, high-capacity storage, and virtualization technology. These provide:
- Protection against hardware faults and failures by hosting redundant workloads in virtual machines (VMs)
- Ability to perform analytics at the edge so normal operations can continue even if cloud connectivity is lost
- Opportunity to update edge deployments with new applications and services in the future
Of course, most HCI platforms do not support OT requirements out of the box. For example, remote IoT edge deployments often require:
- Ability to automatically reconfigure or self-heal if there are system failures, additions, or changes
- Ability to continue operations even if an entire physical node goes down
- Bare-metal performance on par with native hardware, even for applications running in VMs
Intelligent software is needed to implement these reliability and performance features. The NodeWeaver edge cluster execution platform is one such solution that brings these capabilities to HCI systems operating at the edge.
Let the Nodes Manage Themselves
NodeWeaver is an orchestration and management solution that “weaves” multiple endpoints into a large, virtualized edge computing infrastructure. This means that workloads can be deployed in VMs on completely separate physical nodes, so if one endpoint fails, its applications can continue running elsewhere in the infrastructure.
Every node integrates a distributed file system, software-defined networking (SDN), and virtualization components on top of an operating system that runs bare metal on x86 targets (Figure 2). The entire stack consumes as little as 4 GB of memory, making it suitable for most HCI systems.
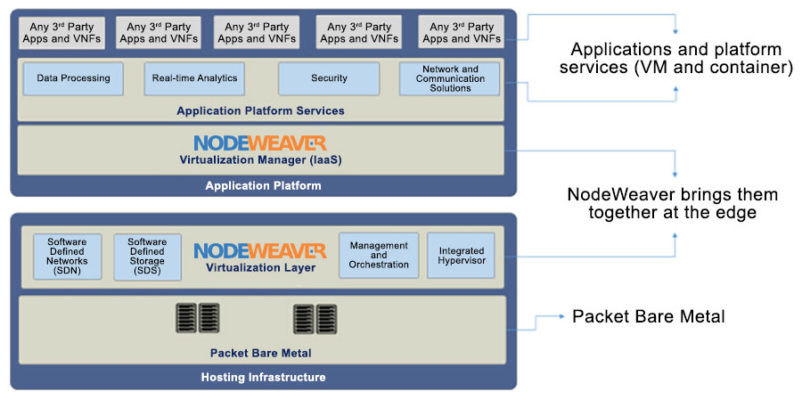
Virtual networks are used to join these nodes into clusters, which can consist of anywhere between 2 and 25 nodes. The distributed file system then replicates application data (or “chunks”) from one node and transmits it to VMs in other nodes using a stochastic process to distribute chunks to the highest-performance nodes with the most available storage.
To ensure chunks are constantly available, NodeWeaver runs a process that checks the entire cluster. If the process discovers that a chunk is missing or damaged, it instructs the file system orchestrator to replicate a new chunk elsewhere in the cluster. So if a storage drive faults or fails, for example, NodeWeaver can “heal” the system by instantiating a new chunk on another operational resource. No user intervention is required.
This process is also the way that NodeWeaver discovers new resources that have been added or if an administrator has made changes to an existing resource.
Hands-free real-time Virtualization
As mentioned, NodeWeaver creates an entirely virtualized environment across physically and geographically distributed nodes. As such, it’s important to note that applications do not view nodes as individual resources. Rather, they view the entire infrastructure as a sea of resources.
But that still doesn’t mean unlimited resources are available on every node.
NodeWeaver assures that workloads are executed efficiently in this environment, using an autonomic load balancer. The load balancer employs a feature called dynamic adaptability, which constantly benchmarks the various workloads running throughout a cluster. It then schedules workloads on the most efficient available hardware based on their quality of service (QoS) requirements. This hardware can include x86-based CPUs, GPUs, FPGAs, and even Intel® Movidius™ accelerators.
In addition, the underlying NodeWeaver OS provides soft real-time guarantees, allowing workloads to be executed at near-bare-metal performance. Again, this is achieved without the need for human intervention.
Can AI Further Automate the Edge?
To meet IoT customer expectations of redundancy, flexibility, and scalability, IoT system architects must design their endpoints with cloud functionality in mind. Not only can this eliminate single points of failure, it also enables autonomous edge environments that function indefinitely even in the absence of local IT support.
But what else could these autonomous edge environments achieve if they added artificial intelligence? A platform could monitor the performance of hardware over time and predict when drives will fail or software will malfunction, allowing maintenance technicians to optimize their service schedules accordingly. Platforms like NodeWeaver are already beginning to integrate probabilistic engines that accomplish this.
Let the edge manage itself.