Building AI Vision Systems in the Real World

A 2019 IDC survey found that 25 percent of organizations deploying AI technology experience a 50 percent failure rate. There were several contributing factors, but the common denominator was an inability to collect, integrate, and manage the data used to train AI models.
And, more specifically, to develop and maintain models based on data that accurately represents conditions in the real world.
“When you’re in the lab, you are working on fixed data sets, but these do not represent the complexity of actual deployments,” explains Vincent Delaitre, Co-Founder and CTO at Deepomatic. “Your lab data set is so small compared to the variety of the real world.”
To illustrate this point, Delaitre cites a partnership with Compass Group, one of the world’s largest catering companies that serves food at many large-scale enterprises. To expedite the lunchtime payment process—which had taken more than five minutes using manual point-of-sale systems—Compass Group sought an automated checkout system that leveraged AI-based object recognition to identify and charge patrons in a fraction of a second.
Of course, this required that neural networks running in the system be able to identify more than 15,000 items that were prepared differently, presented on diverse dishware, and scanned in various lighting conditions. To make things more challenging, items were routinely substituted due to seasonal availability, menu changes, and so on.
Unfortunately, many of these variables are not captured by the fixed data sets used to develop and test AI systems in the lab. In fact, a large number of them may be impractical to test in a lab setting or simply not considered by developers amid the limitless number of cases or events that could present themselves in a real-world deployment.
Without the ability to continuously adapt to varying data, automated checkout systems like those desired by Compass Group will produce error rates so high that they are no less efficient than the traditional manual alternative.
“A” Is for AI. It’s Also for Agile.
One major obstacle that prevents AI-based systems from adapting to unfamiliar conditions is conventional software development. AI systems demand a highly flexible, agile approach that allows developers to quickly identify unexpected phenomena and adjust their training data sets appropriately.
Paradoxically, encountering many of these exceptions means that systems must be deployed in the field so that they can document unanticipated data for future inclusion in more comprehensive, intelligent models.
To kick-start this data-centric feedback loop for the Compass Group, Deepomatic assisted in deploying an edge-based AI system based on its Deepomatic Studio and Deepomatic Run solutions.
Deepomatic Studio is a hybrid AI development and data management platform that allows nontechnical personnel to train, test, and visualize proprietary algorithm performance on top of automatically scalable infrastructure (Figure 1). These algorithms are then deployed into real-world production environments using Deepomatic Run, a Docker-based edge environment that programmatically executes inferencing algorithms on edge devices using a local API.
With @aaeoneurope, @compassgroupuk trained a 1M+ image data set—leading to wait times of less than 10 seconds per customer.
In the case of the Compass Group automated checkout system, algorithms developed in the Deepomatic ecosystem of tools are deployed onto the UP Xtreme board from AAEON Technology, Inc. The UP Xtreme is a cost-efficient, single-board computer powered by 8th Generation Intel® Core™ and Intel® Celeron® processors supporting up to six modules featuring Intel® Movidius™ VPUs for demanding edge inferencing tasks such as computer vision-based object recognition, detection, and so on (Figure 2).

But algorithms developed in the Deepomatic environment are not inherently optimized for UP Xtreme targets, which could result in poor execution time, reduced accuracy, increased power consumption, and other negative consequences for end users like the Compass Group. To avoid these pitfalls, the Deepomatic platform leverages the Intel® OpenVINO™ Toolkit, a cross-platform command-line tool that imports models from various development frameworks and prepares them for ideal performance on Intel® hardware (Figure 3).
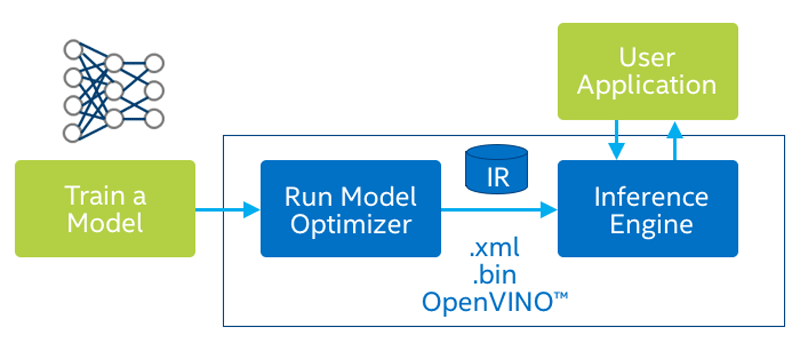
The OpenVINO toolkit is provided as part of the Deepomatic software development kit (SDK). Combined, this solution stack facilitates the bidirectional flow of data needed to continually improve edge AI systems.
“The SDK will connect automatically, download the application on your edge device, and start inferencing and processing all of the information,” Delaitre says. “It’s going to send the data back to the Deepomatic Studio platform, so you can iterate and train a new version of your system—and do this loop of continuous improvement.”
Continuous Improvement for Computer Vision Systems
Using this methodology and infrastructure, the Compass Group was able to train a data set of more than 1 million images to recognize more than 10,000 individual items. The algorithms are now deployed on automated checkout systems at multiple Compass Group locations, enabling wait times of less than 10 seconds per customer and a 92 percent satisfaction rating.
Despite this success, Delaitre continues to caution that these levels of accuracy and performance are the work of many deployments over several years. He points out that error rates were four times higher than their goal at the beginning of the project when deploying the smart checkout system at a new location. And it took two years to completely optimize the system, thus proving the long-term importance of collecting feedback.
Fortunately, AAEON is committed to supporting customers through this new type of real-time development process and throughout their long-term deployment life cycles. In collaboration with Intel®, new initiatives from the company will support certain AI hardware and software solutions stacks for 15 years.
Smarter systems need smarter development infrastructure, and a guarantee that it will be available as long as they need to keep adapting to their environments.
Now that both are available, your only job for them to keep learning is to keep the data flowing.